📌 Label smoothing이란?
Hard target(0또는 1)을 soft target(0과 1사이)으로 만드는 것
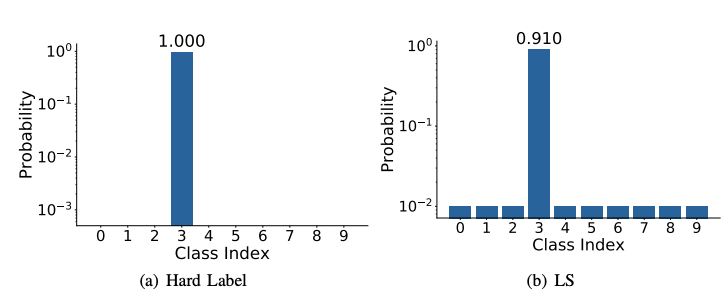
Multi-class 분류 문제에서 사용되는 라벨은 일반적으로 원-핫 벡터 (one-hot vector)를 사용합니다.
원-핫 벡터는 정확히 하나의 클래스만 표현하는 방식으로 정답에 해당하면 1, 나머지는 0으로 넣는 방식입니다.
Label smoothing 기법은 정답 클래스의 비중을 약간 줄이고 나머지 클래스의 비중을 늘리는 기법으로 수식은 다음과 같습니다.
y_kLS = y_k(1-alpha) + alpha/K
K개의 클래스에 대해 smoothing 파라미터를 alpha라고 할 때, hard label y_k를 soft label y_kLS로 만들 수 있습니다.
예를 들면 K = 4이고 y_k=[0,1,0,0]에 대해 alpha = 0.1이면 y_kLS = [0.025,0.925,0.025,0.025]가 됩니다.

❓ Label smoothing의 목적
모델의 over-confidence 문제를 해결
데이터의 label은 잘못되었을 가능성이 언제나 있기 때문에 100% 정확한 Ground Truth으로 보기 어렵습니다.
잘 정제되어 있지 않은 데이터셋으로 모델을 학습하면 잘못된 loss값을 계산하게 되어 학습에 문제를 발생시킬 수 있습니다.
이게 왜 문제가 될까?
Why is this a problem?
You might argue that since I only trained the classifier on animals, of course it breaks when you show it a human, and you’re right. However, in real world systems, we aren’t able to filter out animal images from non-animal images before sending it to the model, so we need it to be robust to garbage input. The animal-human example tries to replicate this on a small scale (one image). Properly quantifying uncertainty is important because we (as practitioners training the models) can’t be confident in the model’s ability to generalize if it assigns arbitrarily high confidence to garbage input.
[출처] https://jramkiss.github.io/2020/07/29/overconfident-nn/
실제로는 잘못 labeling된 데이터가 아니라 학습하지 않은 분류의 데이터가 들어올 경우도 들어옵니다. 이럴 경우, over-confident한 모델은 학습한 분류 중 하나라고 높은 확률로 예측한다는 것입니다.
(동물 분류 모델을 만들었는데, 사람 사진을 넣었더니 98% 확률로 강아지라고 판단)
따라서 Label smoothing을 통해 모델이 정확하지 않은 데이터셋에 치중되는 경향(over-confident)을 막아 모델 보정 (model calibration) 효과를 가질 수 있습니다.
[참고]
https://blog.si-analytics.ai/21
https://towardsdatascience.com/label-smoothing-make-your-model-less-over-confident-b12ea6f81a9a
'Interview Study > AI' 카테고리의 다른 글
| 인공지능(AI), 머신러닝, 딥러닝의 정의 (0) | 2022.02.13 |
|---|---|
| 회귀(Regression)과 분류(Classification) (0) | 2022.01.23 |