극성 감정 분석: 긍정/부정이나 긍정/중립/부정을 분류한다.
ex)영화리뷰나 음식점 리뷰에 적용되기 쉽다
네이버 영화리뷰 데이터를 이용하여 긍정/부정 감정 분석을 해보자
데이터 불러오기
훈련데이터로 15만개, 테스트 데이터로 5만개
https://raw.githubusercontent.com/e9t/nsmc/master/ratings_train.txt
https://raw.githubusercontent.com/e9t/nsmc/master/ratings_test.txt위 사이트에서 데이터들을 다운로드하여 불러온다.
path_to_train_file = "ratings_train.txt"
path_to_test_file = "ratings_test.txt"
#데이터 불러오기
train_text = open(path_to_train_file,'rb').read().decode(encoding='utf-8')
test_text = open(path_to_test_file, 'rb').read().decode(encoding='utf-8')
#텍스트 총 몇자인지 확인
print('Lenth of text: {} characters'.format(len(train_text)))
print('Length of text: {} characters'.format(len(test_text)))
print()
#처음 300자 확인
print(train_text[:300])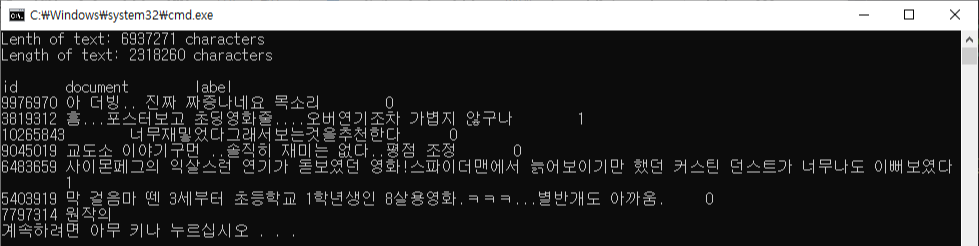
데이터의 각 행은 탭 문자 (\t)로 구분돼 있다.
id: 고유 id
document: 실제 리뷰 내용
label: 긍정/부정을 나타내는 값, (0: 부정, 1: 긍정)
훈련데이터를 만들기
-Y값 (label)
train_Y = np.array([[int(row.split('\t')[2])] for row in train_text.split('\n')[1:] if
row.count('\t') > 0])
test_Y = np.array([[int(row.split('\t')[2])] for row in test_text.split('\n')[1:] if
row.count('\t') > 0])
print(train_Y.shape, test_Y.shape)
print(train_Y[:5])
각 텍스트를 개행 문자 (\n)로 분리한 다음,
해더에 해당하는 부분(id, document, label)을 제외한 나머지 ([1:])에 대해 각 행을 처리한다.
각 행은 탭 문자 (\t)로 나눠진 후에 3번째 원소(index = 2)를 정수(integer)로 변환해서 저장한다.
np.array로 결과 리스트를 감싸서 네트워크를 입력하기 쉽게 만든다.

솔직히 위 두줄이 이해하기가 어려워서 다시 밑에처럼 작성했다.
for row in train_text.split('\n')[1:]:
if row.count('\t') > 0:
train_Y = np.array([int(row.split('\t')[2])])
for row in test_text.split('\n')[1:]:
if row.count('\t') > 0:
test_T = np.array([int(row.split('\t')[2])])근데 결과값이 같게 나오지 않는다.. 왜지? 파이썬 공부를 더 해야겠다.
-X값
입력으로 쓸 자연어를 토큰화(Tokenization)하고 정제(Cleaning)해야 한다.
토큰화: 자연어를 처리 가능한 작은 단위로 나누는 것
여기서는 단어를 사용할 것이기 때문에 띄어쓰기 단위로 나누면 된다.
정제: 원하지 않는 입력이나 불필요한 기호 등을 제거하는 것
def clean_str(string):
string = re.sub(r"[^가-힣A-Za-z0-9(),!?\'\`]", " ", string)
string = re.sub(r"\'s", " \'s", string)
string = re.sub(r"\'ve", " \'ve", string)
string = re.sub(r"n\'t", " n\'t", string)
string = re.sub(r"\'re", " \'re", string)
string = re.sub(r"\'d", " \'d", string)
string = re.sub(r"\'ll", " \'ll", string)
string = re.sub(r",", " , ", string)
string = re.sub(r"!", " ! ", string)
string = re.sub(r"\(", " \( ", string)
string = re.sub(r"\)", " \) ", string)
string = re.sub(r"\?", " \? ", string)
string = re.sub(r"\s{2,}", " ", string)
string = re.sub(r"\'", "", string)
return string.lower()
train_text_X = [row.split('\t')[1] for row in train_text.split('\n')[1:]
if row.count('\t') > 0]
train_text_X = [clean_str(' ') for sentence in train_text_X]
#문장을 띄어쓰기 단위로 단어 분리
sentence = [sentence.split(' ') for sentence in train_text_X]
for i in range(5):
print(sentences[i])
import re: 정규표현식 라이브러리를 불러온다.
clean-str 함수는 다수의 정규표현식을 사용하고 있는데
첫 줄을 제외하면 세 번째 인수인 string에서 첫번째 인수에 해당하는 내용을 찾아서 두번째 인수로 단순히 교체해준다.
첫 줄도 세 번째 인수에서 첫 번째 인수를 찾아서 두 번째 인수로 교채해주는 흐름은 같지만
대괄호안에 ^ = 대괄호 안의 내용을 찾은 다음에, 그에 포함되지 않는 나머지 모두를 선택한다는 뜻
즉, 한글, 영문, 숫자, 괄호, 쉼표, 느낌표...를 제외한 나머지는 모두 찾아서 공백으로 바꾸겠다는 뜻 (예를 들면 이모티콘?)

구두점(.) 같은 기호가 삭제되고 단어 단위로 나눠진 데이터가 생긴 것을 확인할 수 있다.
문장의 길이 맞추기!
네트워크에 입력하기 위한 데이터의 크기(문장의 길이)는 동일해야 하는데
현재는 각 문장의 길이가 다르기 때문에 문장의 길이를 맞춰야 한다.
이를 위해서는 적당한 길이의 문장이 어느 정도인지 확인하고
긴 문장은 줄이고 짧은 문장에는 공백을 의미하는 패딩(padding)을 채워넣어야 한다.
-각 문장의 길이를 그래프로 보기
sentence_len = [len(sentence) for sentence in sentences]
sentence_len.sort()
plt.plot(sentence_len)
plt.show()
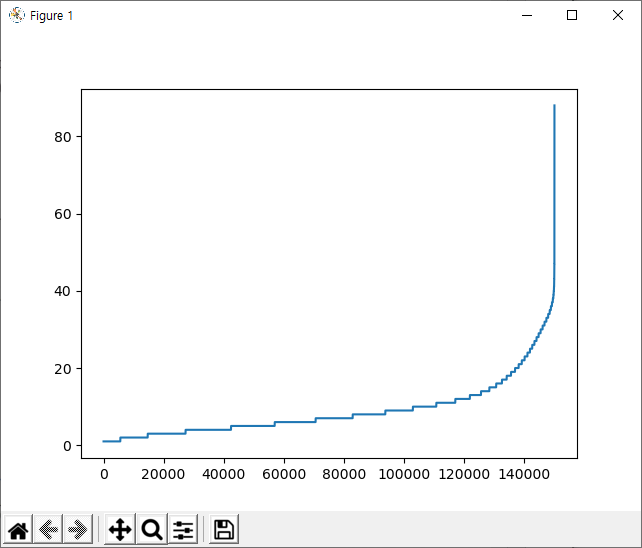
15만 개의 문장 중에서 대부분이 40단어 이하로 구성돼 있음을 확인할 수 있다.
print(sum([int(l<=25) for l in sentence_len]))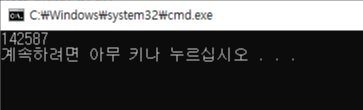
25 단어 이하의 문장의 수는 142587개로 전체의 95%정도
따라서 기준을 25 단어로 잡고 이상은 생략, 이하는 패딩으로 길이를 맞추면 임베딩 레이어에 넣을 준비가 끝난다.
각 단어의 최대 길이 조정하기!
"스파이더맨에서", "스파이더맨이", "스파이더맨을" 등의 단어를 앞에서부터 5글자로 자르면 모두 "스파이더맨"이라는 한 단어가 된다.
이렇게 자르더라도 단어가 가진 의미가 어느 정도 보존되기 때문에 적절한 길이로 자르면 여러 개의 단어에 분산될 수 있는 의미를 하나로 모을 수 있게 된다.
*영어에서는 어간 추출과 표제어 추출이라는 기법으로 단어를 전처리한다. 어간 추출은 "lying"을 ly로 변환하고, 표제어 추출 함수로 "lie"로 변환한다.
sentences_new = []
for sentence in sentences:
sentences_new.append([word[:5] for word in sentence][:25])
sentences = sentences_new
for i in range(5):
print(sentences[i])
패딩을 넣기!
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
tokenizer = Tokenizer(num_words=20000)
tokenizer.fit_on_texts(sentences)
train_X = tokenizer.texts_to_sequences(sentences)
train_X = pad_sequences(train_X, padding='post')
print(train_X[:5])Tokenizer: 데이터에 출현하는 모든 단어의 개수를 세고 빈도 수로 정렬해서 num_words에 지정된 만큼만 숫자로 반환, 나머지는 0으로 반환
tokenizer.fit_on_texts(sentences): Tokenizer에 데이터를 실제로 입력
tokenizer.texts_to_sequences(sentences): 문장을 입력받아 숫자를 반환
pad_sequences(): 입력된 데이터에 패딩을 더한다
문장에서 사용하지 않는 부분은 0을 패딩으로 넣어서 입력의 길이인 25를 맞춘다.
pad_sequences()의 padding인수에는 pre와 post 가 있다.
pre: 문장의 앞에 패딩, post: 문장의 뒤에 패딩

"아"는 25, "더빙"은 884 등의 숫자로 바뀌었다.
세번째 문장은 모두 0으로 표시되고 있는데, "너무재밓었"이라는 단어가 빈도 수에서 상위 20000개에 들지 못해 패딩과 같은 0으로 처리된 것이다. 다섯 번째 문장도 단어 수에 비해 0이 아닌 값을 가진 데이터의 길이가 7로 짧다.
즉 Tokenizer에서 걸러진 단어가 많다는 것을 확인할 수 있다.
Tokenizer의 인덱스와 단어는 Tokenizer.index_word에 저장돼 있다.
학습모델
model = tf.keras.Sequential([
tf.keras.layers.Embedding(20000,300,input_length=25),
tf.keras.layers.LSTM(units=50),
tf.keras.layers.Dense(2, activation='softmax')
])
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.summary()
임베딩 레이어에서 input_length을 25로 지정해서 각 문장에 들어있는 단어를 길이 300의 임베딩 벡터로 변환한다.
loss는 spare_categorical_crossentropy를 사용했다.
여러 개의 정답 중 하나를 맞추는 분류 문제일 때 categorical_crossentropy를 사용하고,
정답인 Y가 희소 행렬일 때는 sparse를 사용한다.
*희소행렬(sparse matrix)은 행렬의 값이 대부분 0인 경우를 가리키는 표현이다.
필요한 정보는 정답 라벨 숫자 하나뿐인데, 표현하기 위해 많은 숫자를 써야될 경우, 그냥 숫자로 표현해도 됨.
([0,0,0,0,0,0,0,0,0,1] 대신 9로 표시하고, [0,0,0,0,1,0,0,0,0,0] 대신 4로 표시)
학습시키기
history = model.fit(train_X, train_Y, batch_size=128, epochs=5, validation_split=0.2)데이터가 많기 때문에 한번에 학습하는 데이터의 양인 batch_size를 128로 설정하고 5 에포크만 학습시켰다.
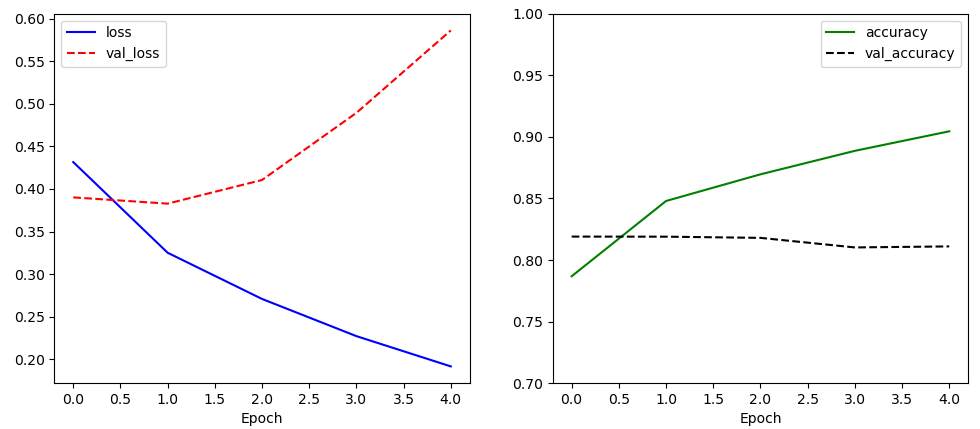
학습 과정에서 loss는 꾸준히 감소하지만 val_loss는 점점 증가하는 것을 확인할 수 있다.
이는 네트워크가 과적합되고 있다는 의미이다.
과적합의 이유는 임베딩 레이어를 랜덤한 값에서부터 시작해서 학습시키기 때문에
각 단어를 나타내는 벡터의 품질이 좋지 않아서이다.
개선 방법으로 임베딩 레이어를 별도로 학습시켜서 네트워크에 불러와서 사용하거나
RNN이 아닌 CNN을 사용하는 방법이 있다.
테스트 데이터를 만들기
test_text_X = [row.split('\t')[1] for row in test_text.split('\n')[1:]
if row.count('\t') > 0]
test_text_X = [clean_str(sentence) for sentence in test_text_X]
sentences = [sentence.split(' ') for sentence in test_text_X]
sentences_new = []
for sentence in sentences:
sentences_new.append([word[:5] for word in sentence][:25])
sentences = sentences_new
test_X = tokenizer.texts_to_sequences(sentences)
test_X = pad_sequences(test_X, padding='post')
model.evaluate(test_X, test_Y, verbose=0)test_text에도 train_text와 같은 변환 과정으 거쳐서 만들었다.
이때 주목할 점은 train_X를 만들 때 학습시켰던 Tokenizer를 그대로 사용!
*위에서 설명했지만, Tokenizer: 데이터에 출현하는 모든 단어의 개수를 세고 빈도 수로 정렬해서 num_words에 지정된 만큼만 숫자로 반환, 나머지는 0으로 반환
훈련데이터와는 다르게 테스트 데이터에서는 어떤 단어가 나타날지 모르기 때문에 Tokenizer는 훈련데이터로만 학습시켜야 한다.
-임의의 문장에 대한 감정 분석
test_sentence = '재미있을 줄 알았는데 완전 실망했다. 너무 졸리고 돈이 아까웠다.'
test_sentence = test_sentence.split(' ')
test_sentences =[]
now_sentence = []
for word in test_sentence:
now_sentence.append(word)
test_sentences.append(now_sentence[:])
test_X_1 = tokenizer.texts_to_sequences(test_sentences)
test_X_1 = pad_sequences(test_X_1, padding='post', maxlen=25)
prediction = model.predict(test_X_1)
for idx, sentence in enumerate (test_sentences):
print(sentence)
print(prediction[idx])

순환 신경망이 입력의 변화에 따라 값이 변하는 것을 확인할 수 있다.
처음에 "재미있을"이라는 단어만 입력됐을 때는 긍정의 확률이 63.7%로 부정보다 높다.
하지만 다른 단어들이 입력되며 확률이 줄어들었다.
test_sentence를 바꿔가면서 테스트를 해보았는데 항상 잘나오지 않는 것을 볼 수 있었다.
친구의 조언에 의하면, 한글은 띄어쓰기로 구분을 하는 것이 정확도가 높지 않다고 알려줬다.
결국 전처리과정을 다르게 하면 임의의 문장의 감성 분석 예측을 더 정확하게 할 것 같다.
***학습모델을 매번 돌리는 것이 불편해서 model.save()와 tf.keras.models.load_model()을 활용했다.
'Machine Learning > Tensorflow' 카테고리의 다른 글
| [순환신경망]GRU 레이어 (0) | 2021.01.25 |
|---|---|
| [순환 신경망] LSTM 레이어 (0) | 2021.01.15 |
| [순환 신경망] SimpleRNN (0) | 2021.01.15 |
| 순환 신경망 (RNN) (0) | 2021.01.15 |